Hi guys! I couldn’t find any information anywhere on how to build a lineage container2dataset or vice versa. Is it even possible? What to do in the S3 case, when the top-level dataset is represented as a container?
<@U05A57K96F2>
Dataset has container aspect. you can set it to container (https://demo.datahubproject.io/dataset/urn:li:dataset:(urn:li:dataPlatform:datahub,Dataset,PROD)/Schema?is_lineage_mode=false&schemaFilter=)
Thx, Siddique!
It is clear that each dataset can be an IsPartOf of the container. The question is different. If I have a spark/flink service that consumes data from a s3 folder (container), which contains partition subfolders (years, months, days, hours - also containers), and only below are dataset files. In this case, how to correctly build a lineage container-dataset? How to calculate container urn? Now it represents like urn:li:container:8aedea34fd2377eae316eca5464c2034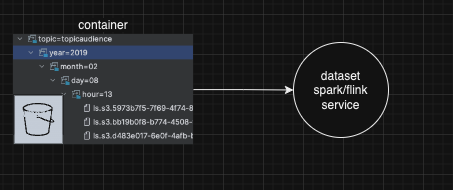
Hi just wondering if you found the solution to container2dataset lineage? I have the same use case and didn’t find anything from the doc. <@U05A57K96F2>
Unfortunately, not yet.