Hi everyone! how are you?! I created a spark ingestion on databricks, the pipeline appears on the UI with the right startedAt time, but with 0 tasks… What it could be? I setted spark.sql.legacy.createHiveTableByDefault to false, my application do: df.write.mode(‘overwrite’).saveAsTable(tablename, path=pathname)
On log4j logs DataHubSparkListener apperars on only on SQL Started execution event
<@U04N9PYJBEW> might be able to speak to this!
Hi Bruno, I’m doing alright, hbu? Hopefully we can get this resolved for you soon! Unfortunately I’m not familiar with our spark source, <@UV14447EU> can you take a look here?
<@U04QRNY4ZHA> <@U04N9PYJBEW> <@UV14447EU>
Hey Guys! thank you for the help! I have some more data that should help you:
I’m running a DBR 10.4 with Spark 3.2.1 Job on a Standalone cluster via Databricks API. The job is running using Spark Python Task
My Datahub version is: 0.10.4.2
Spark lineage jar is: 0.10.5-6rc1
Spark confs:
extraListeners
rest server
remove partition pattern = true (tested true and false with same result)
coalesce jobs = true (with this config set to true i was able to get a task on the UI with the same name as the app name but without any dataset or lineage info)
databricks cluster
Pipeline always have Started At and Completed At, but without any lineage information
I already tested with spark 3.1.2 and jar 0.10.5 same result
All my tables are hive external tables , physical files are stored on Azure Data lake storage, but it is mounted on databricks dbfs
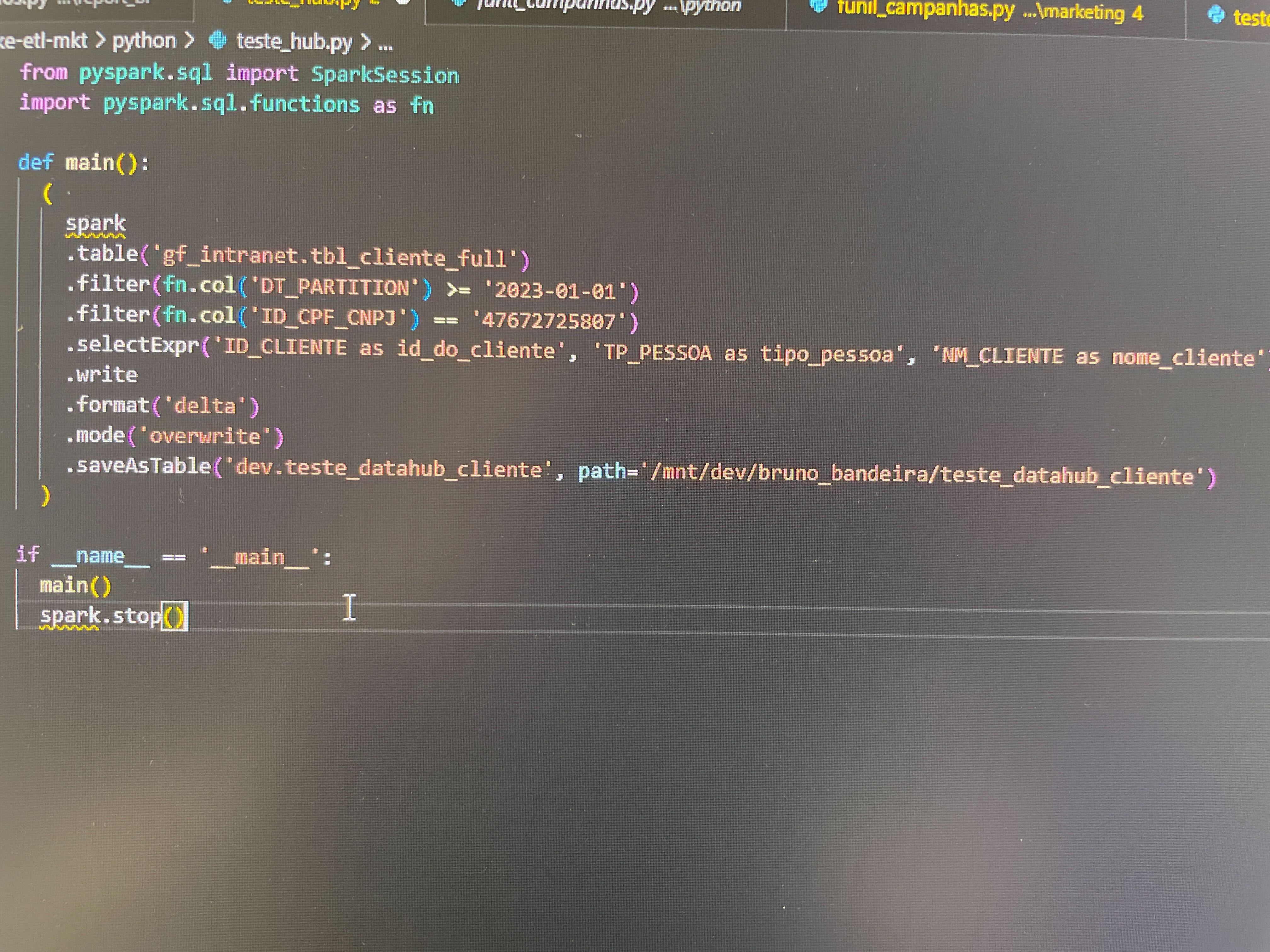
Also, I tried to set up debugging logs but the datahub documentation is for log4j and my databricks cluster is using log4j2, is it possible to configure it?
all tables on my spark application are delta
Update:
I tried updating my jar to 0.10.5-6rc2
Tested with different spark versions and applications using saveAsTable, save , sparkSQL without success…
Same result, Pipeline shows on the UI with Start time, when I use spark.stop() at the end it shows Completed At data on the UI also, but databricks jobs fails since it’s not supposed to use stop on databricks. But always without any data about lineage or tasks…
Does someone has any idea what to do more? thanks!!
<@UV14447EU>
Those are the only logs datahub appears here (But debug logs are disabled) :
23/08/30 19:23:42 INFO SparkContext: Registered listener datahub.spark.DatahubSparkListener
23/08/30 19:24:29 INFO AsyncEventQueue: Process of event SparkListenerSQLExecutionStart(executionId=0, …) by listener DatahubSparkListener took 7.124870504s.
There are no McpEmitter INFO logs
> Unfortunately it is a known and yet unsolved issue that Databricks doesn’t call the onApplicationEnd event.
> We will need to do further investigation into why this is happening there and what we can do about it.
Got it, thanks <@UV14447EU> , this impact lineage info also?
scan and write tables
I think you should have some lineage but not full lineage as on SparkListenerSQLExecutionEnd event it should send in -> https://github.com/datahub-project/datahub/blob/e7d140f82df393b98821f8a49e74ae3995a01ead/metadata-integration/java/spark-lineage/src/main/java/datahub/spark/DatahubSparkListener.java#L266|https://github.com/datahub-project/datahub/blob/e7d140f82df393b98821f8a49e74ae3995[…]k-lineage/src/main/java/datahub/spark/DatahubSparkListener.java
just for a quick test, please can you try to write out in a non-delta format (like parquet or json)?
Sure, i’ll give it a try! brb, thank you
<@UV14447EU> same output ![]() pipeline appears on the UI, with StartedAt and 0 tasks
pipeline appears on the UI, with StartedAt and 0 tasks